Frequently Asked Questions for Play-by-Play Dataset
Each season’s NBA playbyplay dataset comes up with 2 types of files: 1) Individual CSV files for all games played in the regular season and the playoffs. 2) A season-to-date CSV file where all CSV game files are combined. Having this file, you can analyze the whole season stats in one sheet. In brief, our database-friendly (each play presented in a row) log includes every in-game movement such as: “Active players on the court”, “event time (remaining/elapsing)”, “play length & id”, “activity type (substitution/shot/free throw/turnover/foul committed & drawn/rebound/assist/jump ball etc.)”, “shot location” and “shot coordinates”.
Download the sample dataset and open the Excel file where descriptions for all columns have been already provided. Keep in mind that, those descriptions do not appear on the season game logs, so we recommend you to keep the sample file easily accessible until you get familiar with the play-by-play fields.
To give you an idea: Inside the combined CSV file of the 2016-2017 season, there are 1311 individual games and 603,494 rows; which makes ~460 rows per game. The size of the 2016-2017 dataset is 389 MB and becomes 36.82 MB when zipped.
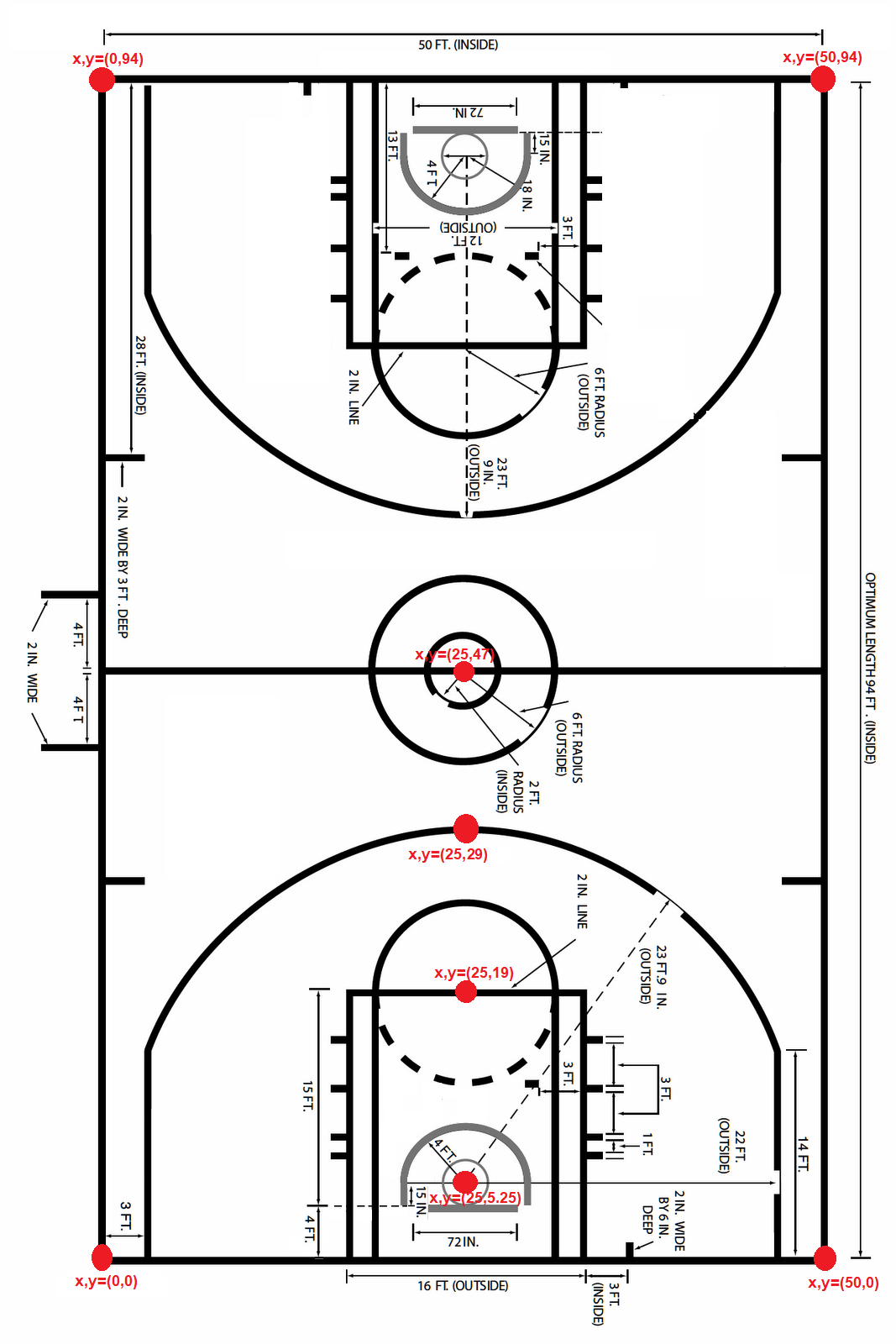
A standard NBA basketball court is 50 feet wide, 94 feet long.
We provide shot locations in two ways:
1) X-Axis, Y-Axis values.
2) X-Axis and Y-Axis values are converted to X, Y coordinates in terms of feet which reflect a standard NBA basketball court dimension.

We provide shot locations in two ways:
1) X-Axis, Y-Axis values.
2) X-Axis and Y-Axis values are converted to X, Y coordinates in terms of feet which reflect a standard NBA basketball court dimension.
Due to human errors made while charting the plays, there will be cases where the results of the sequences are inputted incorrectly or the order of the events might be wrong.
Errors on such as;
– unclassified (offensive/defensive) rebounds,
– disorder in the flow of: missed shot >> offensive rebound >> field goal attempt,
– made field goals which are accidentally inputted 4 points or more,
– zero points inputted on made free throws,
have already been corrected by us.
Errors on such as;
– unclassified (offensive/defensive) rebounds,
– disorder in the flow of: missed shot >> offensive rebound >> field goal attempt,
– made field goals which are accidentally inputted 4 points or more,
– zero points inputted on made free throws,
have already been corrected by us.
Each game log has been named with details such as; “game date”, “game id”, “road team initials” and “home team initials” Example: [2013-10-29]-0021300001-ORL@IND.csv
We have developed a proprietary algorithm in which, substitutions and the relevant game events (points, fouls, getting fouled, assist, steals and etc.) that are assigned to players are taken into account. Note that; despite being a very rare situation, if the player does not record anything or did not take part in any game event while he’s on the court, the chances are our algorithm might not be 100% accurate.
Our data has been reviewed and made use of by big-data analysis/insight extraction platforms such as Omnisci. We have also proudly collaborated with many data journalists and academics who have leveraged our data to create great content, and articles. Even a book is written by our friends at University of Brescia